password
Created time
Jun 22, 2025 02:41 AM
type
status
date
slug
summary
tags
category
icon
✍️ 引言 (Hook)
AI Agent正从“技术魔法”走向“生产力工具”,而多智能体(Multi-Agent)系统,无疑是这股浪潮中最令人兴奋的前沿。它承诺通过AI的集体智慧,解决远超单个模型能力的复杂问题。然而,从一个惊艳的原型到一个能在生产环境中稳定运行、创造商业价值的系统,中间隔着一道巨大的鸿沟。
这道鸿沟要如何跨越?Anthropic团队在构建其强大的Claude多智能体研究系统时,已经为我们趟出了一条路。本文将以他们的实战经验为核心蓝图,深入解析构建企业级多智能体系统的可行性、核心方法论、关键原则与落地考量,希望能为您提供一份来自一线、切实可行的行动指南。
🎯 核心要点
- 可行性所在:对于信息繁杂、路径不定的开放性问题(如市场研究、技术追踪),多智能体通过并行化,能有效扩展解决问题所需的“智能带宽”,其性能远超单个最强Agent。
- 架构蓝图:Anthropic验证的**“编排者-工作者”(Orchestrator-Worker)模式**,是一个企业可以放心参考、高度可复用的成熟架构。
- 四大成功支柱:系统能否成功落地,取决于四大核心原则的执行力:① 赋能式提示工程、② 原子化工具设计、③ 非确定性评估体系、④ 生产级工程纪律。
- 关键考量:多智能体并非万能。理解其边界(尤其是在强序列化任务上的局限性)是做出正确技术选型的第一步。
📖 文章正文
一、 可行性与时机:为什么现在要关注多智能体?
在单一LLM调用已成常态的今天,我们为什么需要更复杂的多智能体?答案在于问题的复杂性已经超出了单个上下文窗口的“智能带宽”。
对于真正的开放性、探索性任务,单一、线性的AI流程力不从心。而多智能体系统,通过模拟一个专家团队的“分工-协作”模式,完美地解决了这个问题。
核心优势:并行化扩展智能。
Anthropic的内部评估提供了强有力的证据:在处理“广度优先”的查询时,由一个首席Agent和多个子Agent组成的多智能体系统,性能比单打独斗的最强Agent高出90.2%。这背后的根本原因,是通过并行执行,系统能在单位时间内消耗更多的Token、探索更多的路径、处理更多的信息,从而容纳了更复杂的推理过程。对于企业而言,这意味着能够更快、更全面地获得决策洞察。
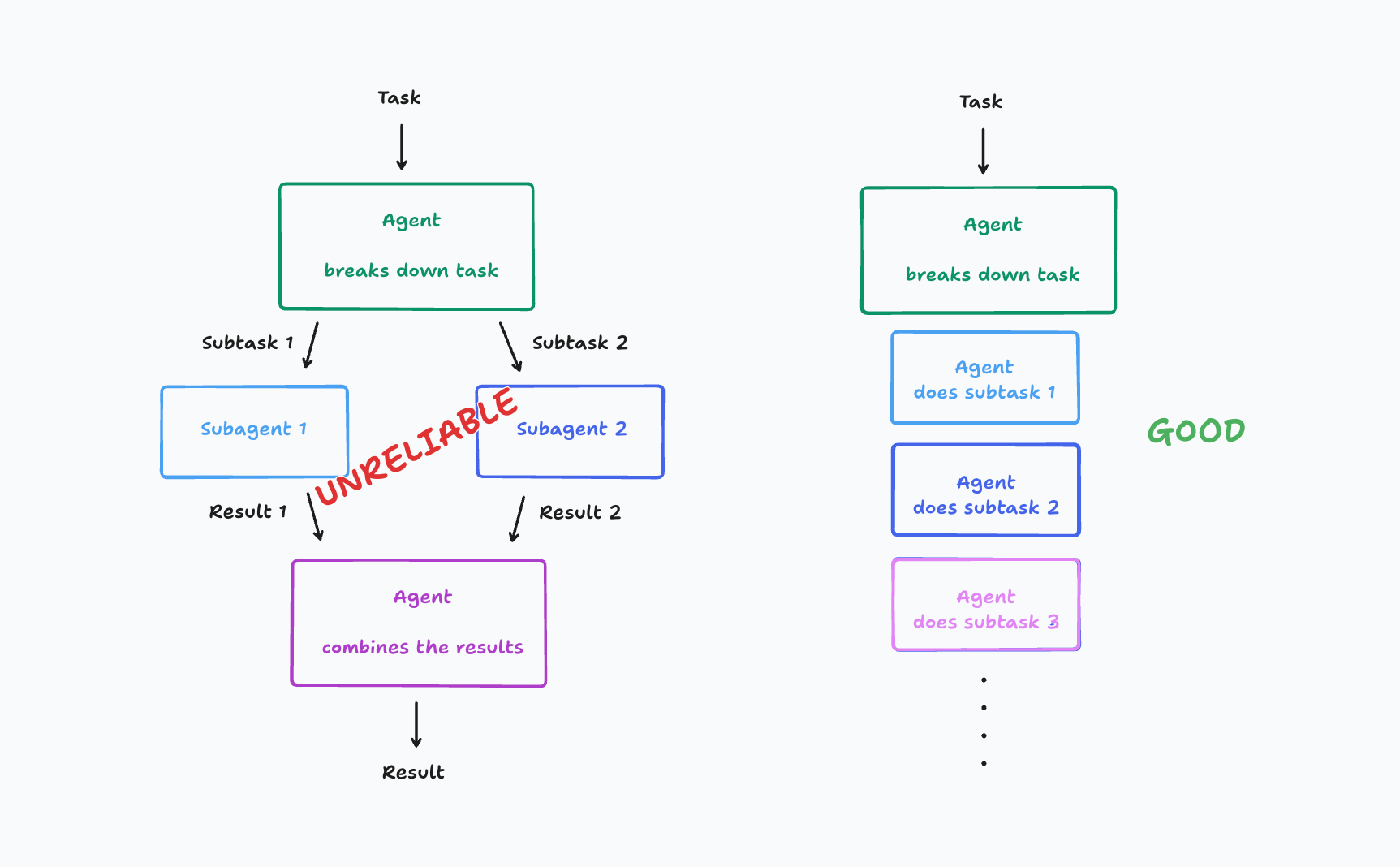
二、 架构蓝图:企业可复用的“编排者-工作者”模式
企业落地新技术,最需要的是一个稳定、可理解的架构。Anthropic的“编排者-工作者”模式正是这样一个理想蓝图。

工作流程解析:
- 首席研究员 (LeadResearcher / Orchestrator):作为“大脑”和“项目经理”,它接收用户请求,制定总体研究计划,并将其存入“记忆”中以防丢失。
- 任务分解与授权 (Decomposition & Delegation):首席Agent将大任务分解为多个并行的子任务,并为每个子任务生成一个“子研究员”(Subagent / Worker),赋予其明确的目标和工具权限。
- 并行研究与提炼 (Parallel Execution):每个子Agent独立使用搜索等工具进行探索,并自我评估结果质量,然后将提炼后的关键信息返回给首席Agent。
- 综合与迭代 (Synthesis & Iteration):首席Agent汇总所有子Agent的发现,判断信息是否充分。如果需要,它可以启动新一轮的研究或调整策略。
- 引用与交付 (Citation & Delivery):研究结束后,所有材料交给专门的“引用Agent”,负责核对来源、确保结论有据可查,最终生成一份高质量的报告。
架构图:
Code snippet
具体工作流:
当用户提交查询时,系统会创建一个 LeadResearcher 代理,该代理将进入迭代研究流程。LeadResearcher 首先仔细考虑该方法并将其计划保存到 Memory 中以持久保存上下文,因为如果上下文窗口超过 200,000 个令牌,它将被截断,因此保留计划很重要。然后,它会创建具有特定研究任务的专用子代理(此处显示了两个,但可以是任意数量)。每个 Subagent 独立执行 Web 搜索,使用交错思维评估工具结果,并将结果返回给 LeadResearcher。LeadResearcher 综合这些结果并决定是否需要更多研究 — 如果需要,它可以创建额外的子代理或改进其策略。一旦收集到足够的信息,系统就会退出研究循环并将所有发现传递给 CitationAgent,后者会处理文档和研究报告以确定引用的特定位置。这可确保所有声明都正确归因于其来源。最终的研究结果(包括引文)将返回给用户。

三、 成功落地的四大核心原则
从原型到生产,Anthropic总结的这四大原则,是每个企业都应铭记于心的行动纲领。
- 原则1:为Agent注入“研究方法论”——提示工程的升维
- 从“指令”到“赋能”:不要只告诉Agent做什么,要教会它“如何思考”。例如,通过提示词引导Agent采纳“先广后深”的研究策略,并要求它写下思考过程。
- 明确授权:给子Agent的指令必须包含清晰的目标、输出格式和任务边界,避免任务漂移和重复劳动。
- 让AI改进AI:利用最强模型(如Claude 4)作为“提示工程师”,让它诊断失败案例并自动优化指令,能显著提升系统效率。
- 原则2:将工具视为“感官”——工具设计的艺术
- 接口即命运:工具的API描述必须清晰、准确、无歧义,这是Agent能否正确使用工具的决定性因素。
- 并行调用是关键:务必让子Agent能够并行调用多个工具。Anthropic的经验表明,仅此一项改动就将复杂查询的研究时间缩短了高达90%。
- 原则3:拥抱“非确定性”——评估体系的变革
- 从小处着手,快速迭代:项目早期,一个包含约20个真实用例的小型测试集,就足以发现重大问题。不要等到有完美的评估集再开始。
- 规模化评估靠LLM-as-Judge:对于研究报告这类开放性输出,使用一个强大的LLM作为“裁判”,根据一份包含事实准确性、完整性等维度的评分细则来打分,是实现规模化、一致性评估的有效手段。
- 人类评估是最后防线:自动化评估无法发现所有问题,尤其是那些需要领域知识和常识判断的细微错误。人工测试永远不可或缺。
- 原则4:敬畏“工程深渊”——生产级的工程纪律
- 状态管理与容错:Agent系统是有状态的,一个步骤的失败可能污染整个后续任务。必须构建强大的容错和恢复机制(如从中断处继续)。
- 可观测性优先:由于其非确定性,传统的断点调试不再适用。必须建立全面的生产追踪系统,监控Agent的决策路径、工具调用和交互结构,才能系统性地诊断问题。
- 平滑部署:采用“彩虹部署”等策略,让新旧版本的系统并存,逐步切换流量,确保不中断正在运行的长任务Agent。
四、 关键考量与边界:另一种声音的启示
在拥抱多智能体架构时,保持清醒的认知同样重要。Cognition AI 提出的“单Agent循环”观点,为我们精准地标定了多智能体模式的适用边界。
- Cognition AI的核心观点:他们认为,对于软件开发这类强序列化、需要紧密反馈循环的任务,多Agent间的通信开销和协调复杂性反而会成为累赘。此时,让一个“全栈天才”式的单Agent在“思考->行动->观察”的循环中快速迭代,是更优的选择。
- 给我们的启示:
- 任务性质是第一考量:在技术选型前,必须深入分析你的核心问题。它更像需要集思广益的“市场研究”(适合多Agent),还是更像需要精益求精的“编码调试”(可能更适合单Agent)?
- 警惕不必要的复杂性:不要为了“多Agent”而“多Agent”。如果一个简单的单Agent循环就能解决问题,那就不要引入复杂的编排层。
- 多Agent的价值在于“真并行”:只有当你的任务能被分解成多个可以真正并行执行、且子任务间依赖性较低的模块时,多智能体架构才能发挥其最大威力。
🚀 企业落地行动建议
- 启动评估:首先,清晰地定义你希望Agent解决的商业问题,并参照上述“关键考量”评估其任务性质,判断多智能体架构是否为最佳选择。
- 多代理系统之所以有效,主要是因为它们有助于花费足够的代币来解决问题。Multi-Agent可能花费的token是普通LLM对话的15倍还多。所以Multi-Agent统需要任务价值足够高的任务,以支付更高的性能。
- MVP先行:从一个简化的“编排者-工作者”架构开始(如1个首席Agent+2个功能固定的子Agent),验证核心协作流程和商业价值。
- 优先投资可观测性:在编写第一行业务代码前,就应规划如何追踪Agent的决策路径、工具调用历史和状态变化。这笔投资将在未来为你节省无数的调试时间。
- 建立两级评估体系:立即着手建立一个由少量核心用例组成的“人工评估集”用于日常回归,同时探索使用LLM-as-Judge进行更大范围的自动化评估。
- 组建跨职能团队:成功的Agent项目需要产品、工程、AI算法和领域专家的紧密合作,尤其是在工具设计和评估环节。
💡 总结
多智能体系统已经走过了概念验证阶段,进入了工程实践的深水区。Anthropic的经验雄辩地证明了其可行性和巨大潜力。对于企业而言,成功的关键在于:选择正确的问题域,采用成熟的架构蓝图,并严格遵循四大核心原则,同时对潜在的工程复杂性保持敬畏。
这条路充满挑战,但对于那些希望利用AI集体智慧解决顶层复杂问题的企业来说,现在,正是出发的最佳时机。
参考:

How we built our multi-agent research system
On the the engineering challenges and lessons learned from building Claude's Research system
Cognition | Don’t Build Multi-Agents
Frameworks for LLM Agents have been surprisingly disappointing. I want to offer some principles for building agents based on our own trial & error, and explain why some tempting ideas are actually quite bad in practice.